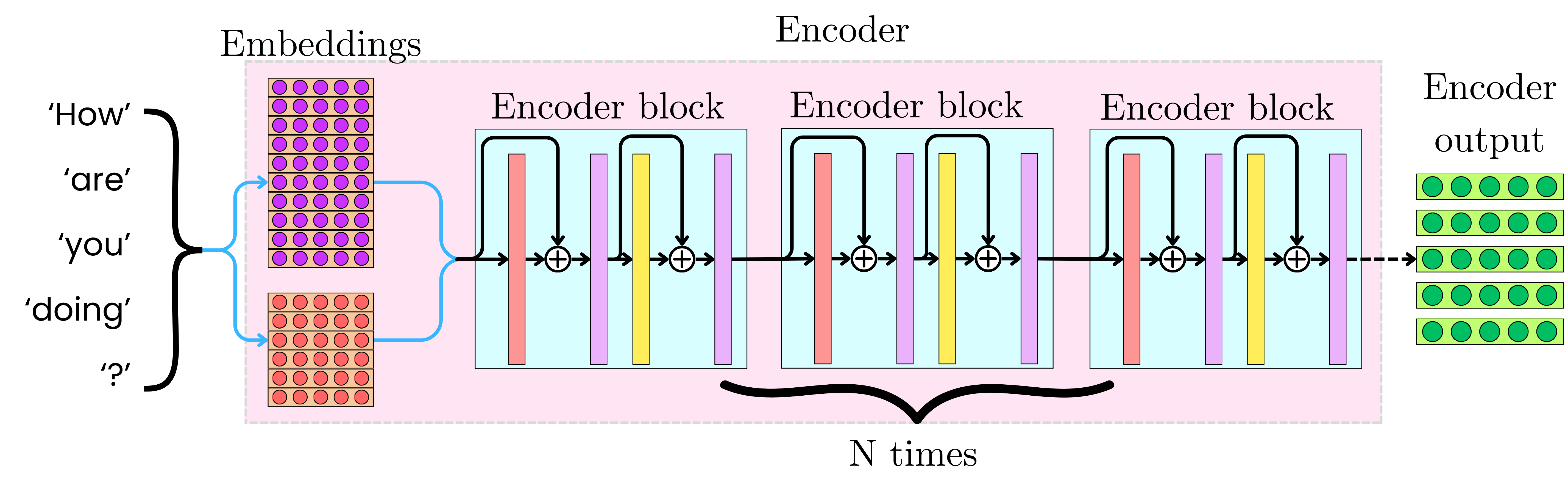
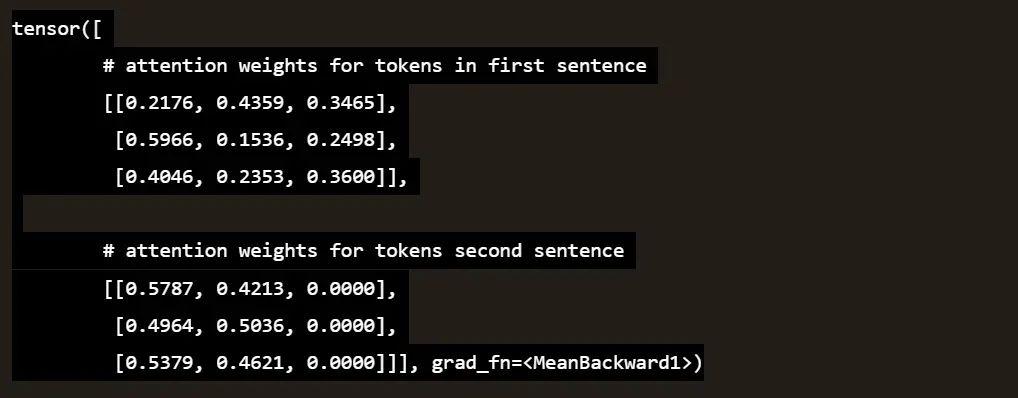
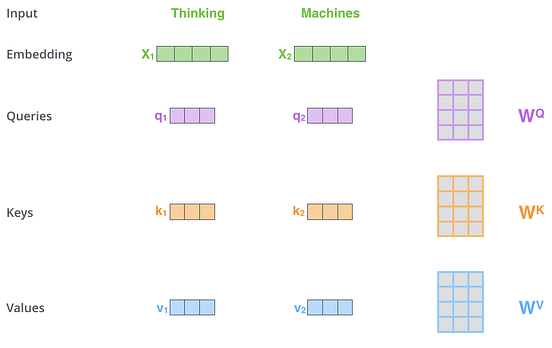
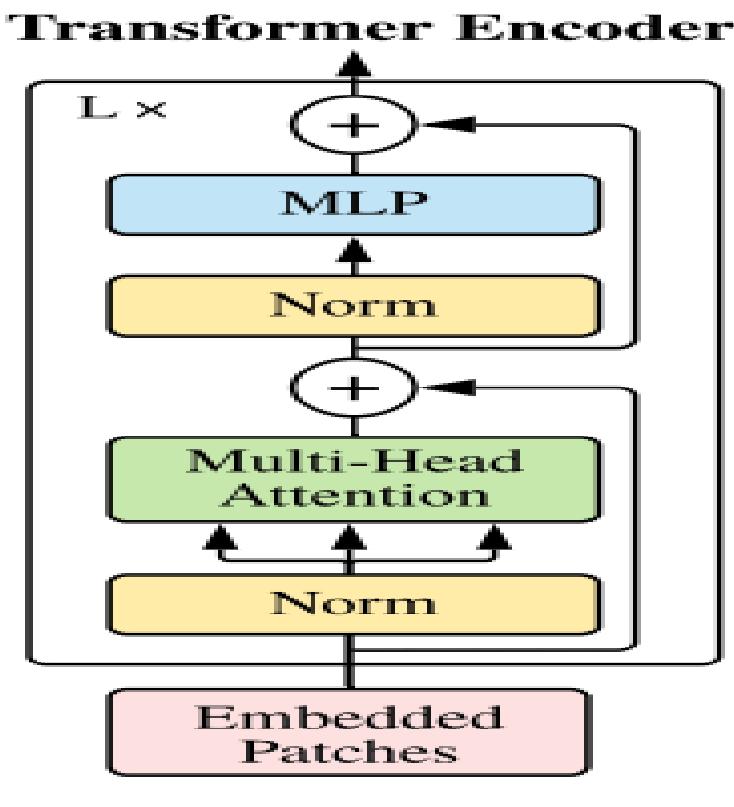
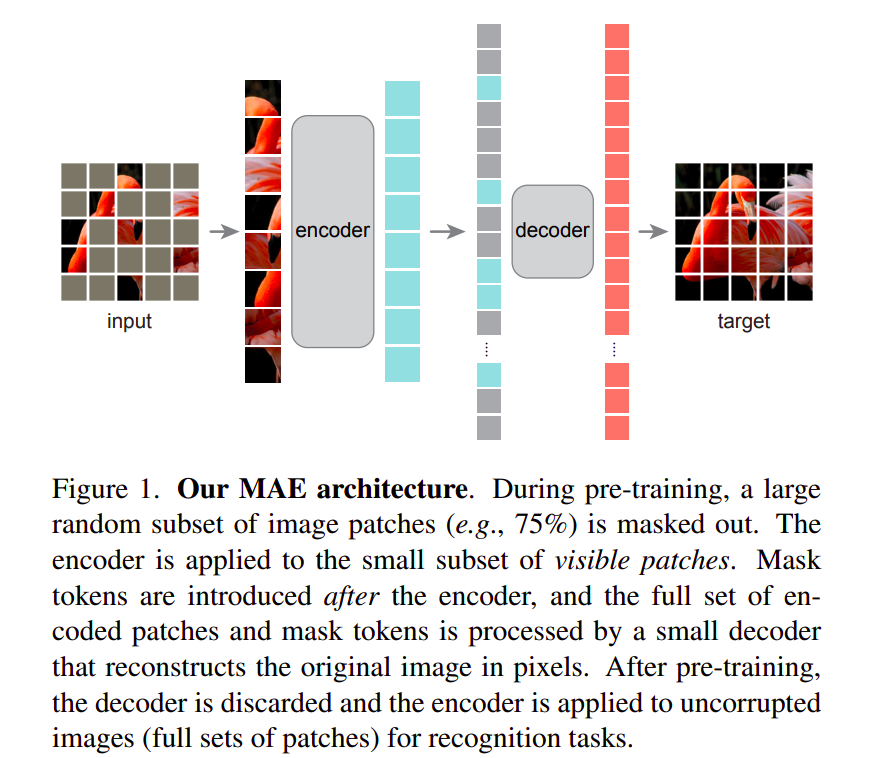
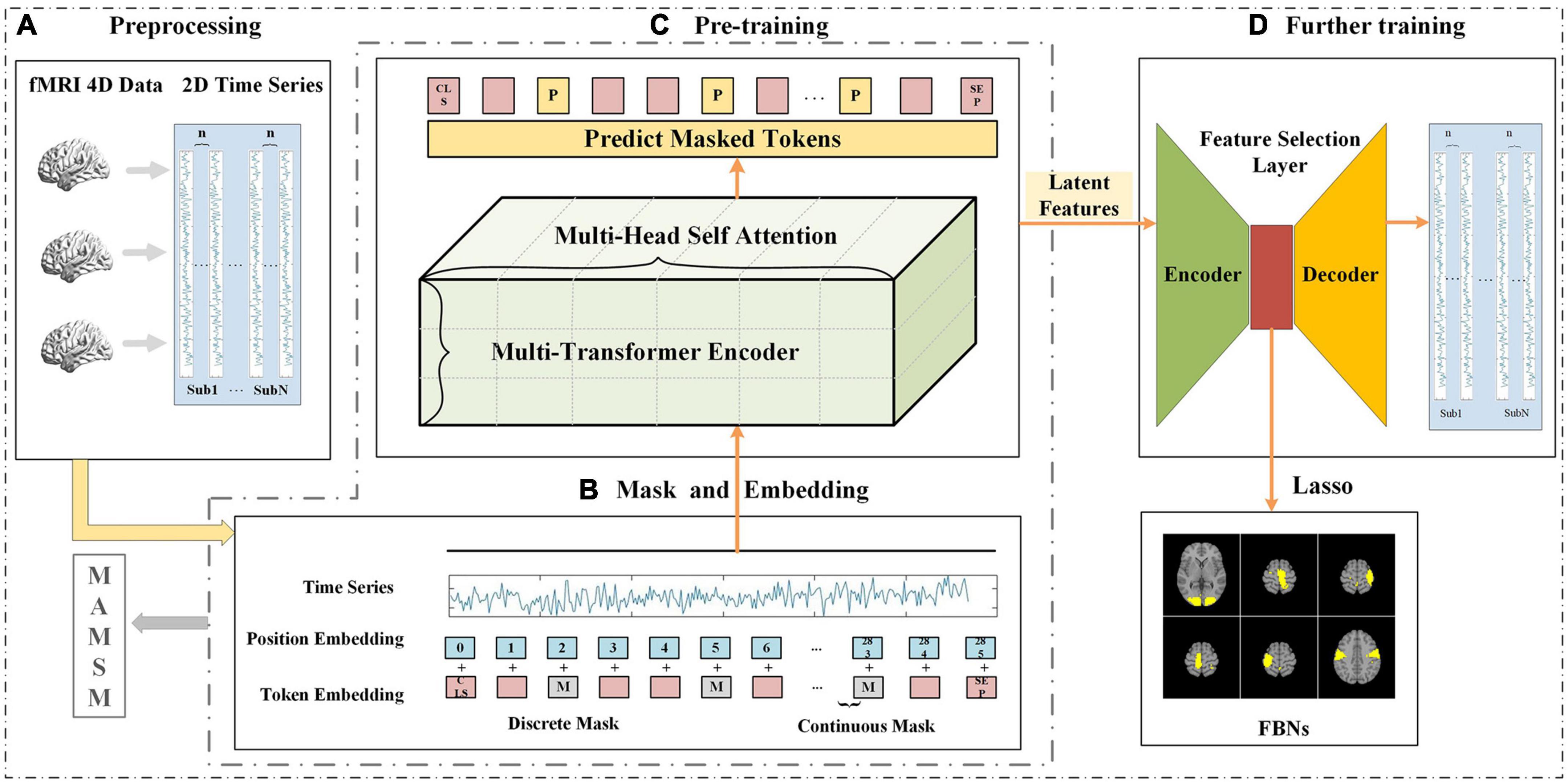
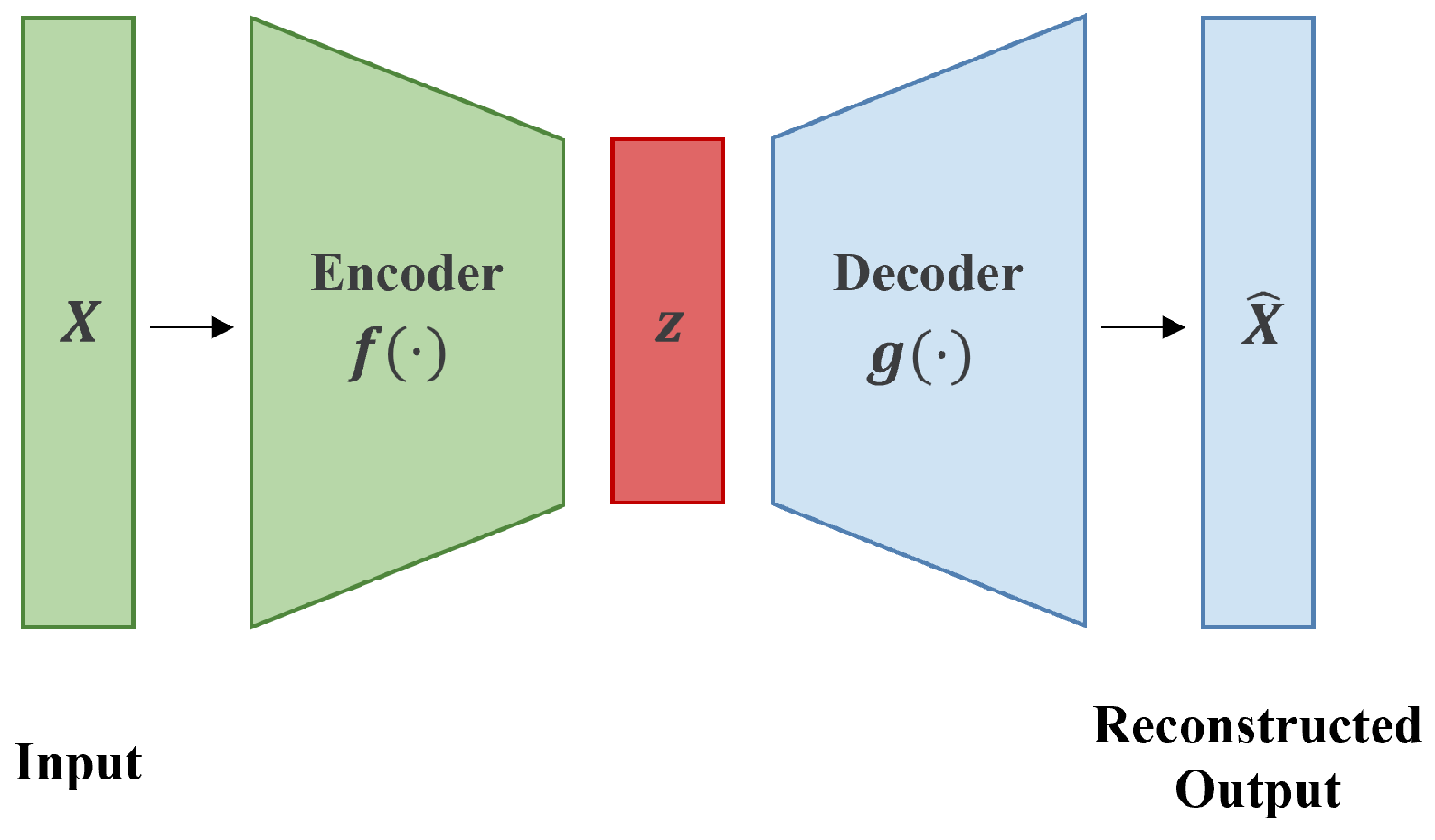
Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
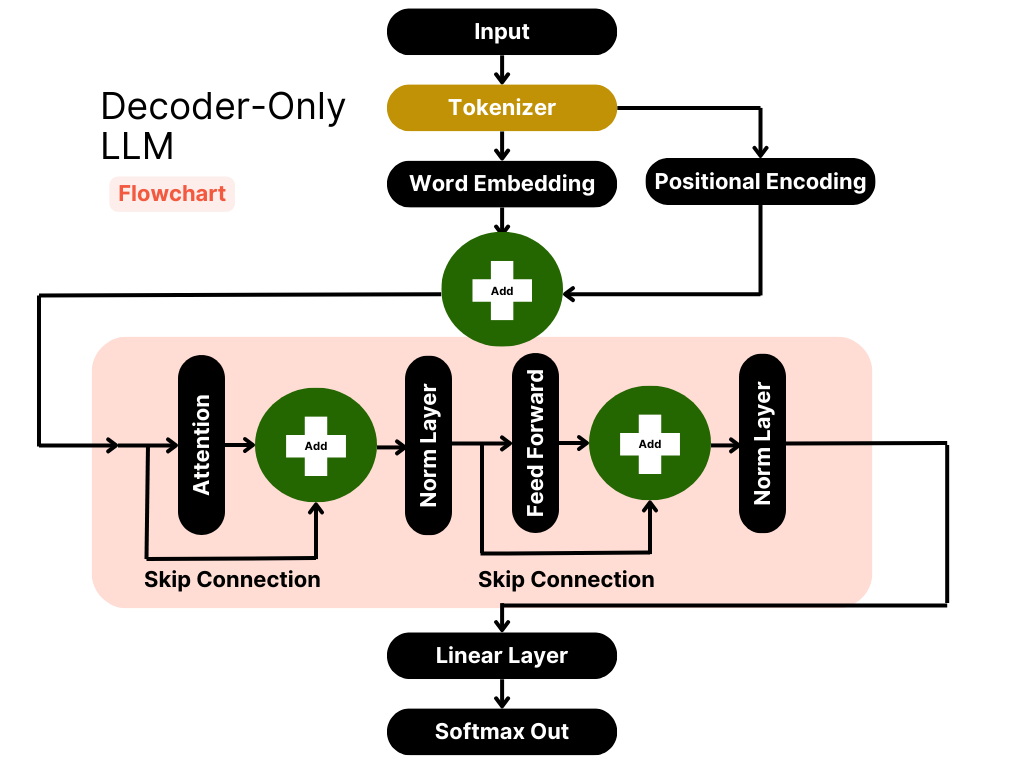
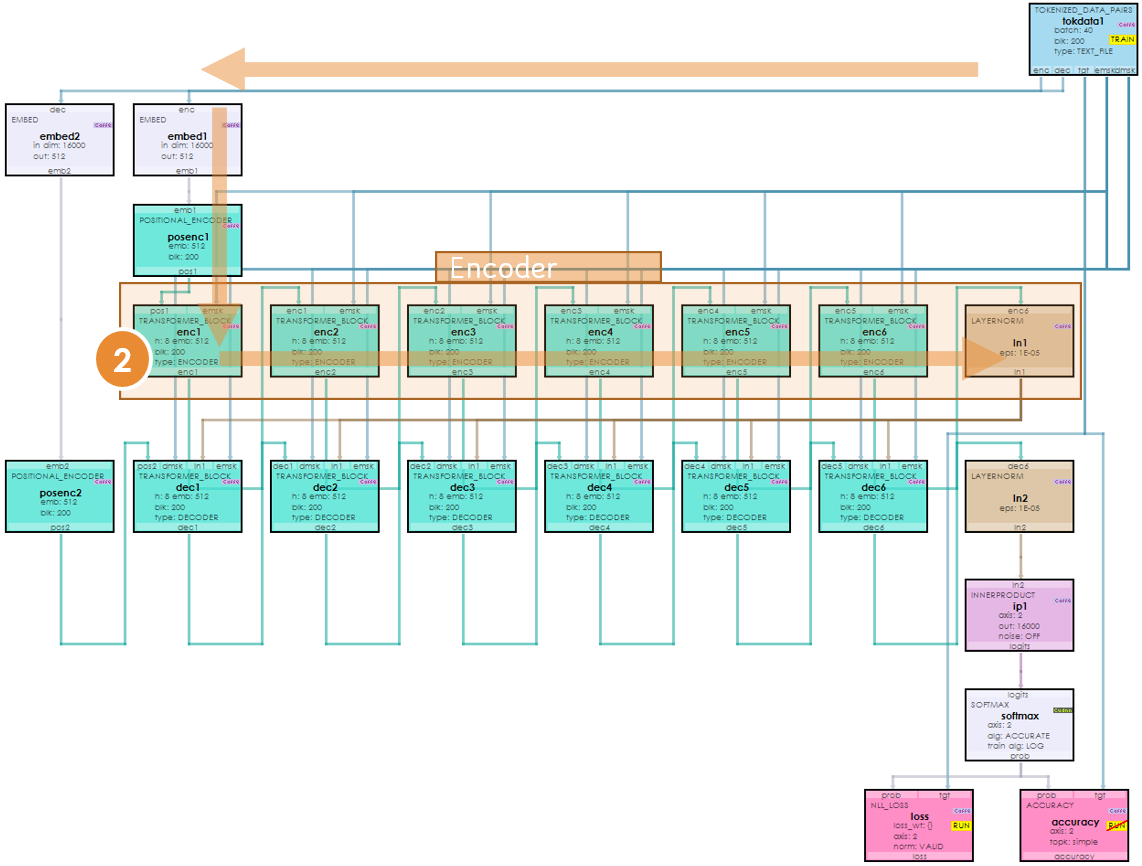
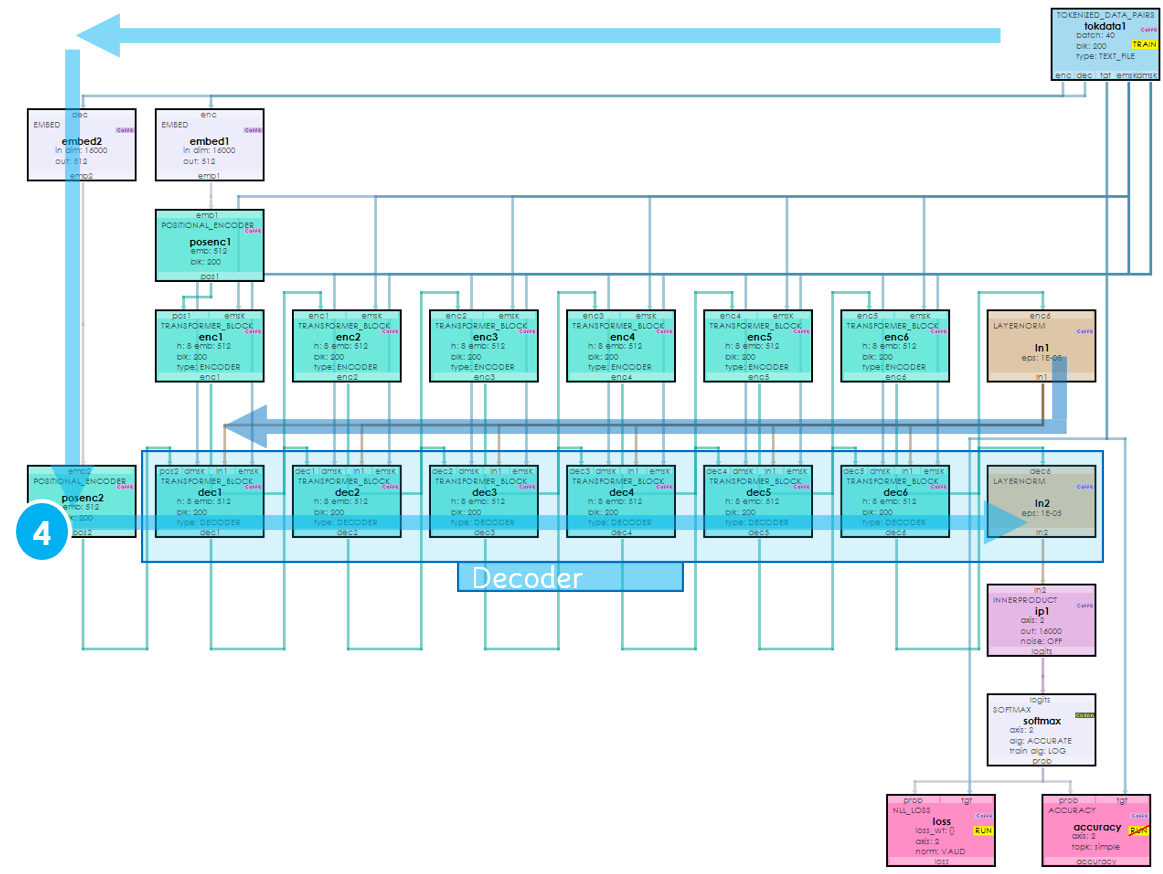
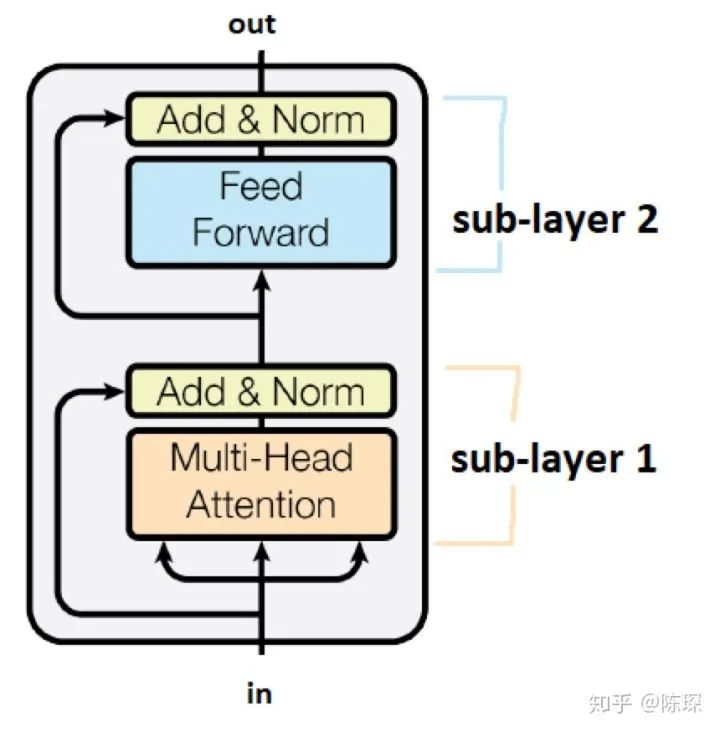
Joining the Transformer Encoder and Decoder Plus Masking ...
Question on masking in transformer encoder · Issue #158 · hirofumi0810 ...
Transformer Encoder Self-Attention pad masking is applied to only one ...
Transformer: Using Decoder input masking when only having a Transformer ...
Masking in Transformer Encoder/Decoder Models - Sanjaya’s Blog
Implementing Transformer Encoder Layer From Scratch - Sanjaya’s Blog
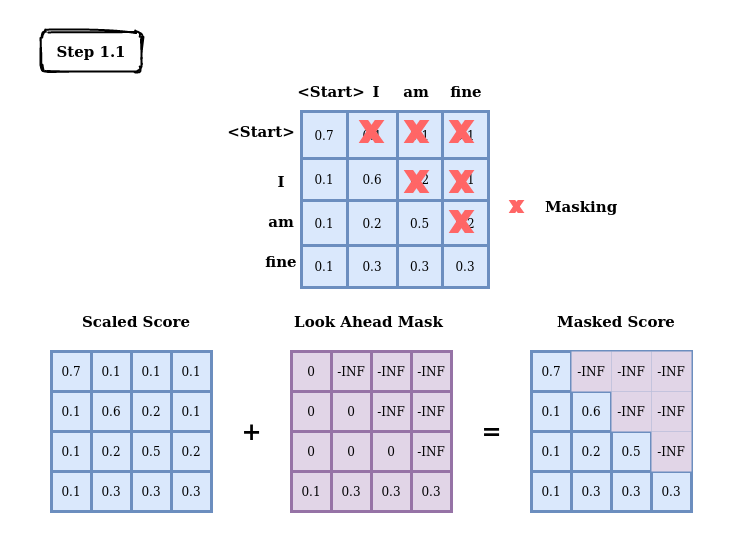
A Simple Example of Causal Attention Masking in Transformer Decoder ...
Implementing a Transformer Encoder from Scratch with JAX and Haiku 🤖 ...
Structure of transformer encoder layer. | Download Scientific Diagram
Transformer 模型介绍(四)——编码器 Encoder 和解码器 Decoder - 技术栈
Encoder only Transformer based classification, with a simple version of ...
(a) The architecture of an transformer encoder layer. (b) The ...
The architecture of the Transformer encoder layer. The differences from ...
The structure diagram of the Multimodal Transformer Encoder in MMVC ...
Transformer : encoder 및 decoder (Masked Self-attention)
Diagram of Transformer Encoder. | Download Scientific Diagram
Visually Walking Through a Transformer Model
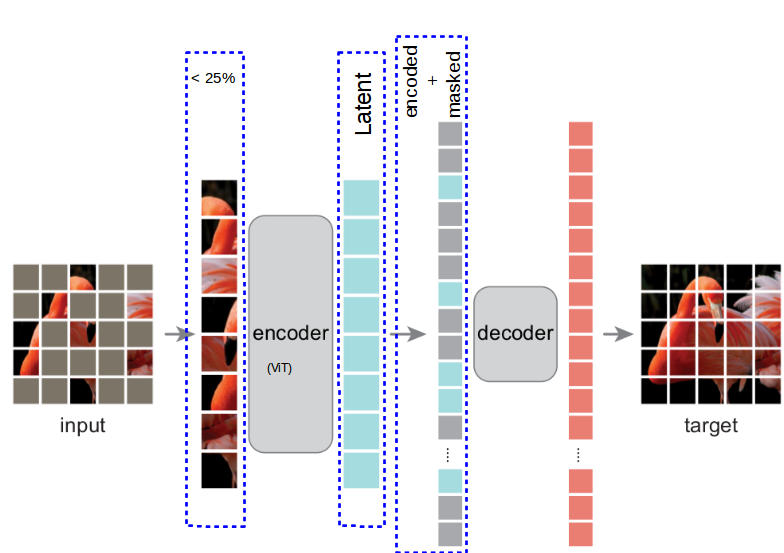
Masked Autoencoder Transformer at Theresa Sotelo blog
Masked Autoencoder Swin Transformer at Samara Smalling blog
Transformer -decoder mask篇. 接續上篇的Transformer -encoder mask篇… | by 任書瑋 ...
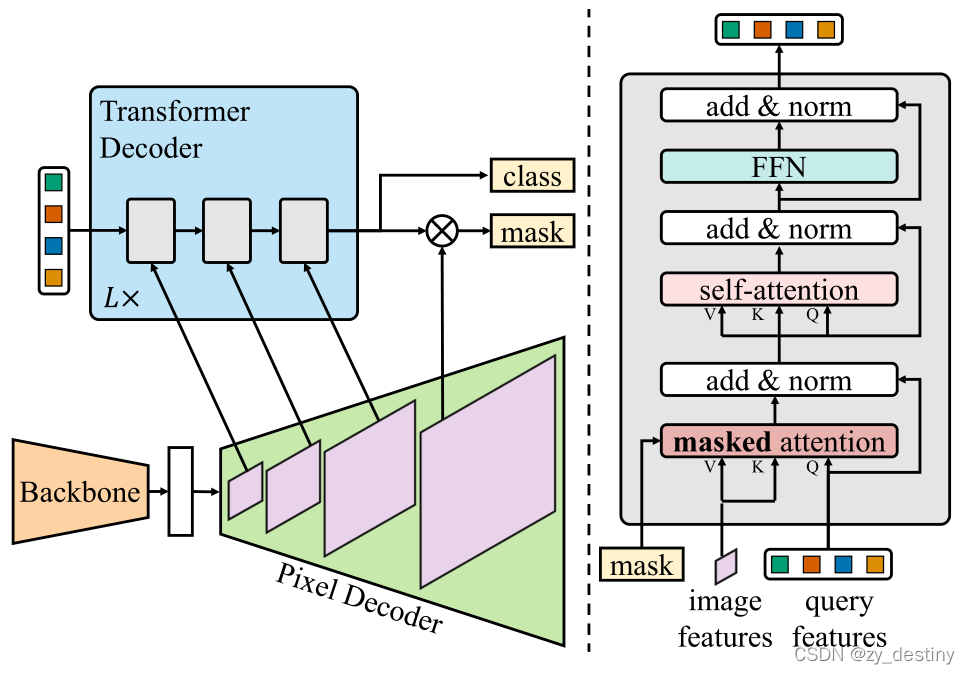
Mask2Former architecture. Each grey block in the transformer decoder ...
The graphical representation of Bidirectional encoder representations ...
Transformer -encoder mask篇. 這篇會著重介紹實際使用Transformer… | by 任書瑋 | Data ...
【Mask2Former】Masked-attention Mask Transformer for Universal Image ...
Self-attention masking for T5 encoder? - 🤗Transformers - Hugging Face ...
Architecture of Bidirectional Encoder Representations from Transformers ...
“Encoder/Decoder” in a Transformer – Lechuck Park
Illustration of the Transformer based encoder-decoder model. | Download ...
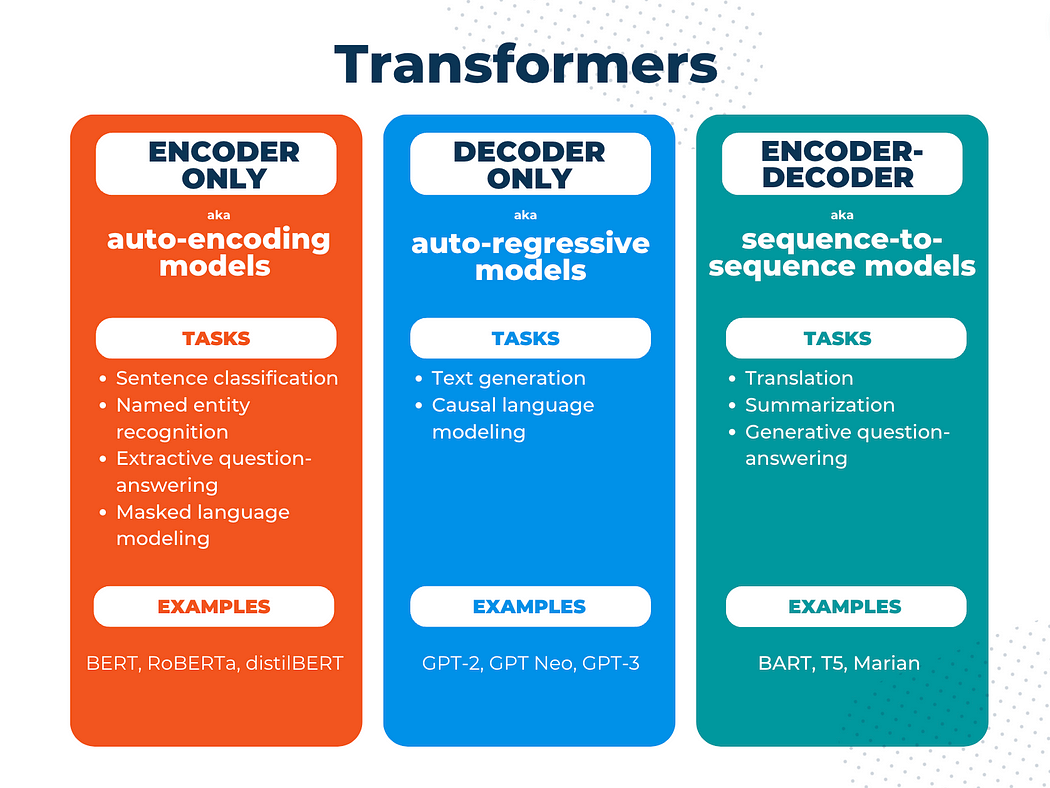
🧠 Three Core Transformer Architectures: Encoder-Only, Decoder-Only, and ...
Efficient Transformer Encoders for Mask2Former-style models
Revisiting Mask Transformer from a Clustering Perspective
Encoders and Decoders in Transformer Models - MachineLearningMastery.com
MaskFormer2 : Masked-attention Mask Transformer for Universal Image ...
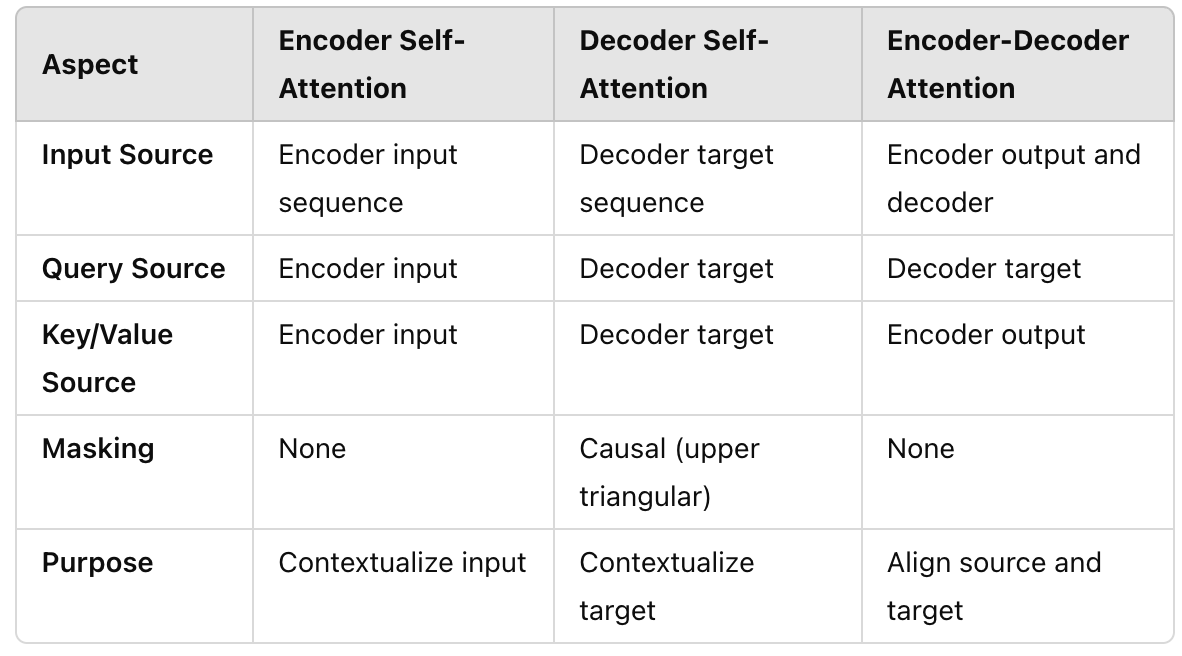
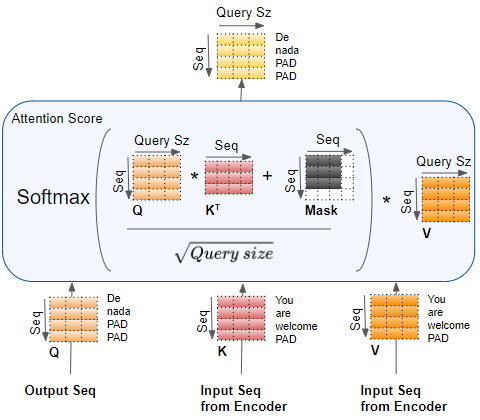
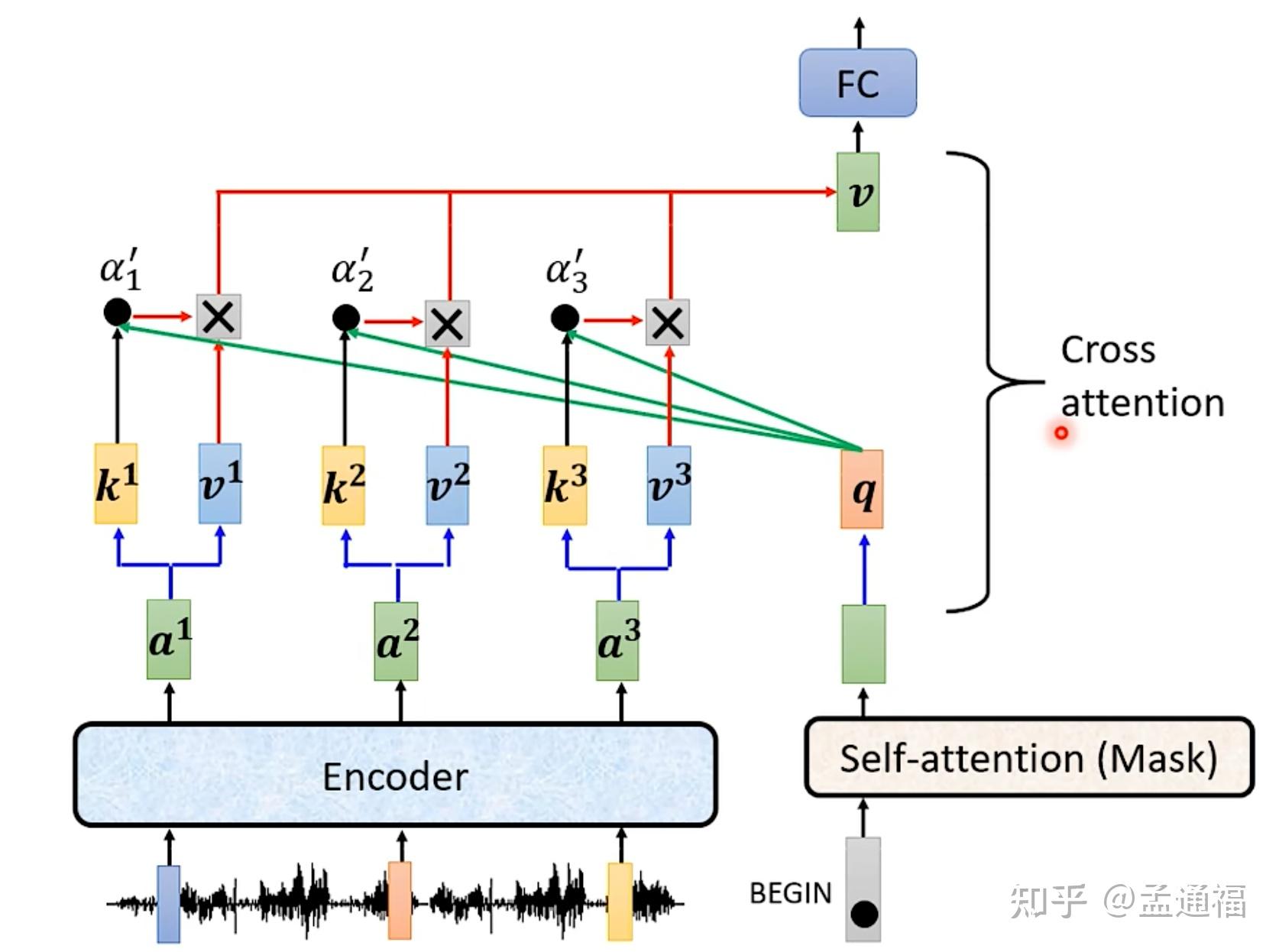
Cross-Attention: Connecting Encoder and Decoder in Transformers ...
BERT Model – Bidirectional Encoder Representations from Transformers ...
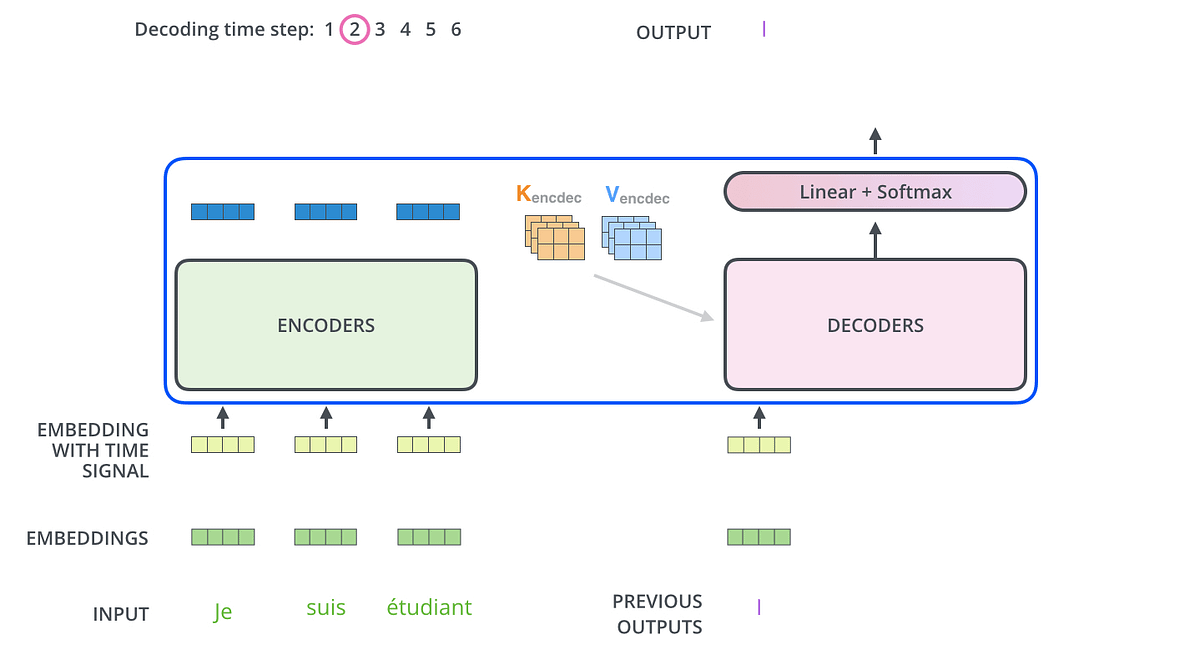
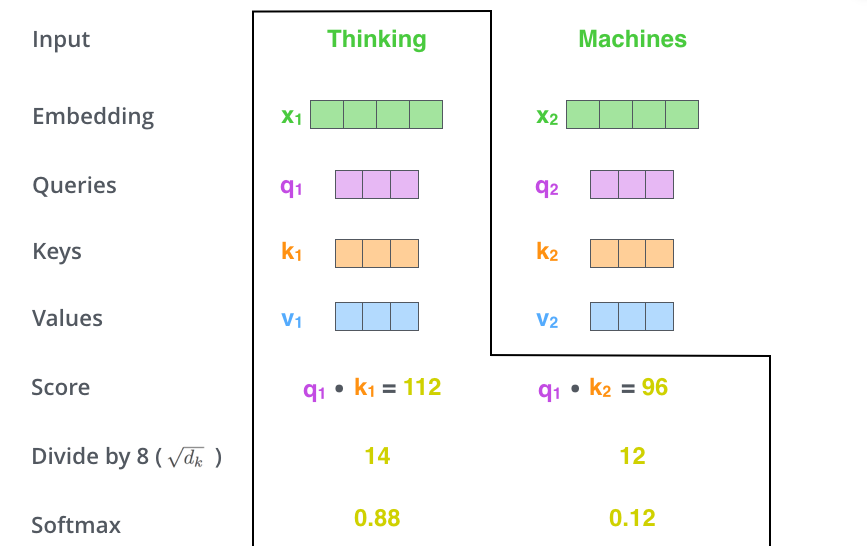
The Illustrated Transformer – Jay Alammar – Visualizing machine ...
How does Transformer models work | DataDrivenInvestor
(PDF) Mask-CTC-based Encoder Pre-training for Streaming End-to-End ...
deep learning - How does the mask work in the Transformer if it ...
Bidirectional Encoder Representations from Transformers – Wikipedia
[2401.06274] Transformer Masked Autoencoders for Next-Generation ...
Encoder Performance - Industry Today - Leader in Manufacturing ...
Overview of the transformer encoder. | Download Scientific Diagram
Explain the Transformer Architecture (with Examples and Videos) - AIML.com
Overview of the Transformer Encoder. | Download Scientific Diagram
An overview of Bidirectional Encoder Representations from Transformers ...
Efficient Transformer Encoders for Mask2Former-style models | AI ...
PMT: Plain Mask Transformer for Image and Video Segmentation with ...
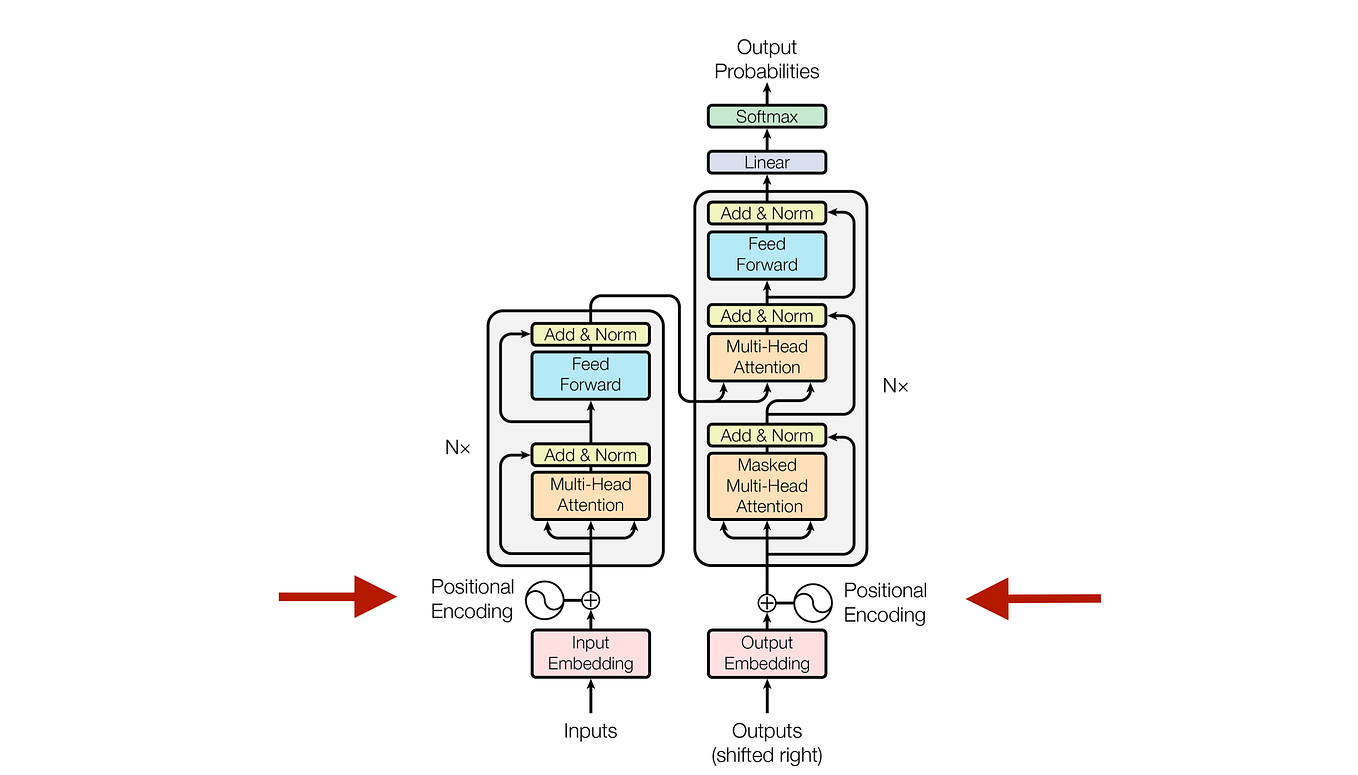
Attention Is All You Need: The Original Transformer Architecture
The detail of the mask used in the transformer encoder. The gray square ...
Transformer Encoder/Decoder结构中的掩码Mask介绍 - 知乎
Figure 2 from Masked Auto-Encoding Spectral–Spatial Transformer for ...
Architecture diagram of transformer encoder.
Illustration of transformer encoder. In our transformer encoder, we ...
The architecture of transformer. The transformer is an encoder-decoder ...
[2005.11978] MASKED PRE-TRAINED ENCODER BASE ON JOINT CTC-TRANSFORMER
[CS224n] Lecture 10 : Pertaining transformer
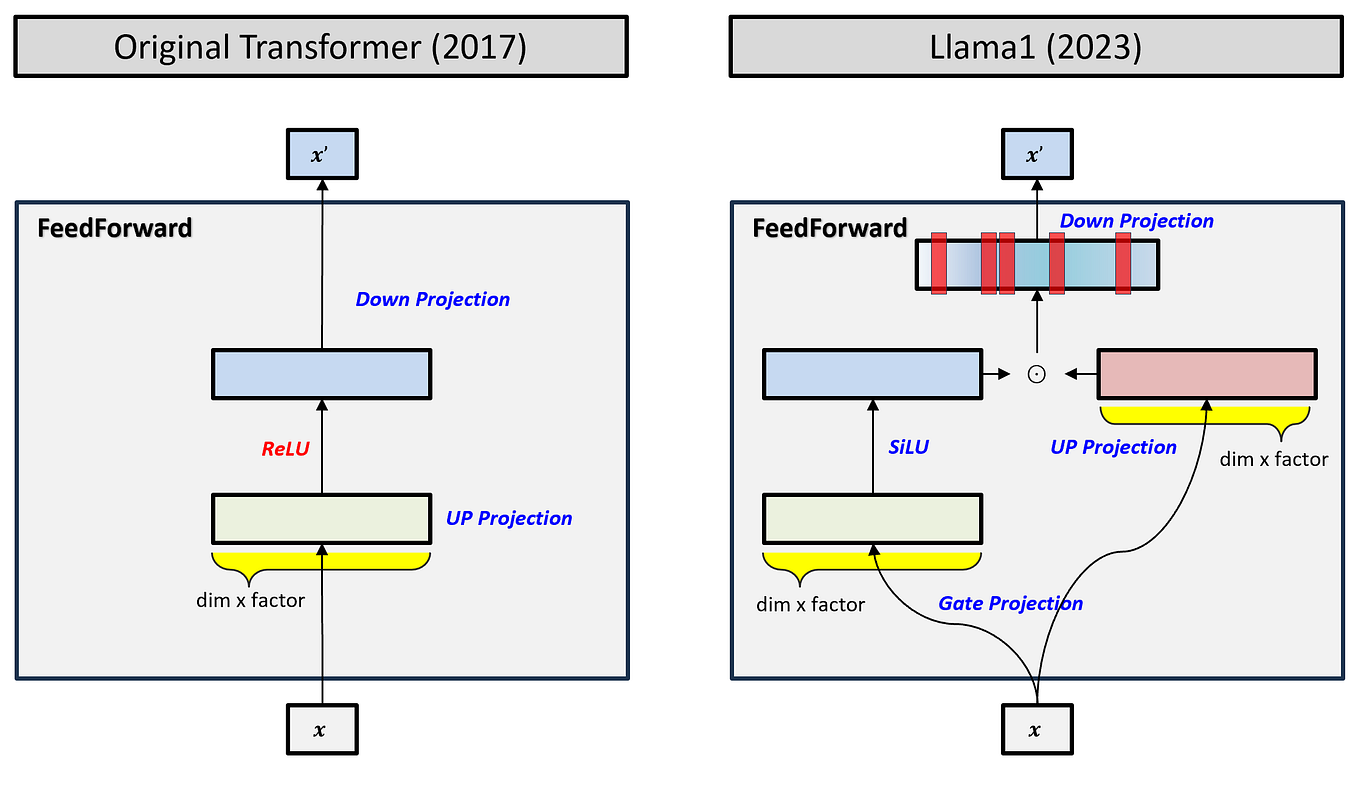
Understanding The Transformer Architecture
Figure 1 from Apply Masked-attention Mask Transformer to Instance ...
Transformer 从零解读 - kingwzun - 博客园
What Is Encoder And Decoder In Computer Architecture at David Oldham blog
Transformer相关——(7)Mask机制 | 冬于的博客
machine learning - Why do we mask input tokens for the decoder in a ...
Working of Encoders in Transformers - GeeksforGeeks
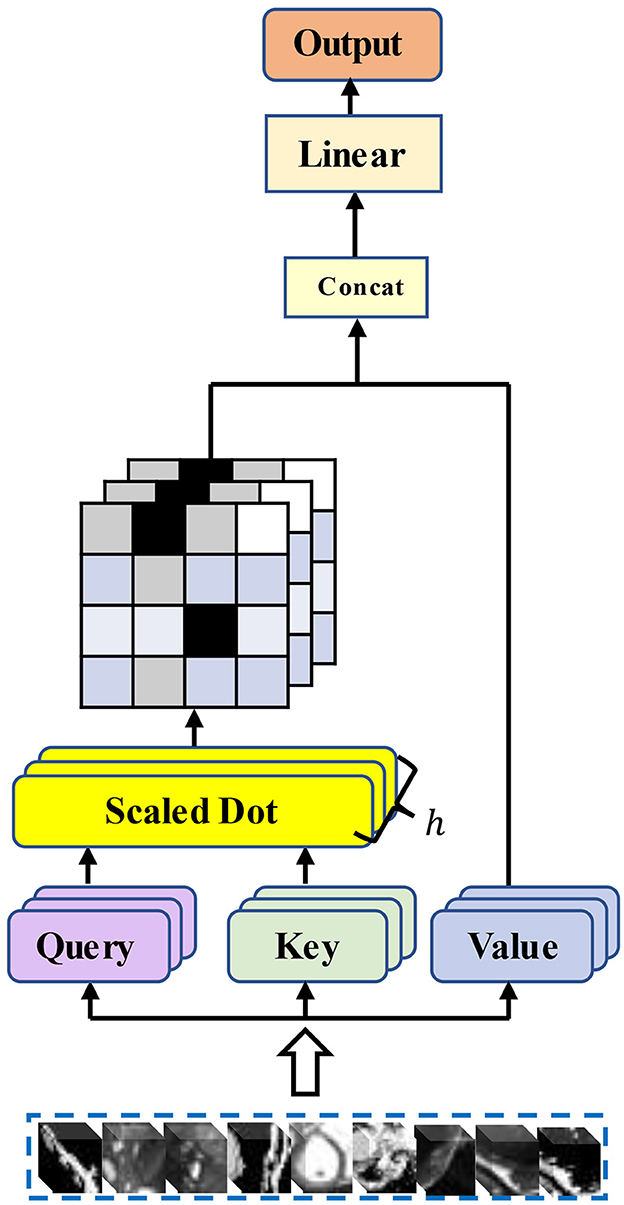
Transformers Explained Visually - Multi-head Attention, deep dive ...
Transformers — Visual Guide
【Pytorch】Transformer中的mask - 知乎
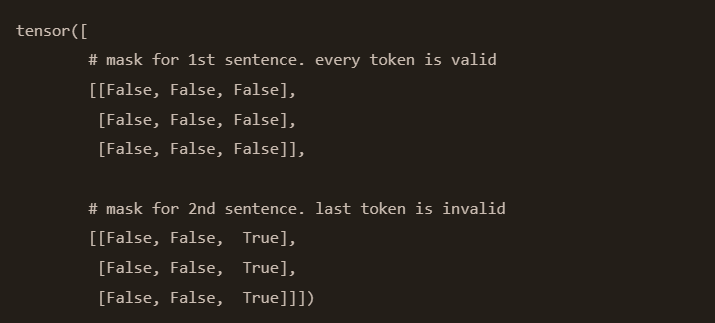
Intuition about the application of padding masks and look-ahead masks ...
Chapter 17 | Sebastian Raschka, PhD
Explainable AI: Visualizing Attention in Transformers - MLOps Community
Transformers - Part 7 - Decoder (2): masked self-attention - YouTube
10分钟带你深入理解Transformer原理及实现-轻识
🚀 Excited to share that EoMT (Encoder-only Mask Transformer) has ...
Transformer39~-CSDN博客
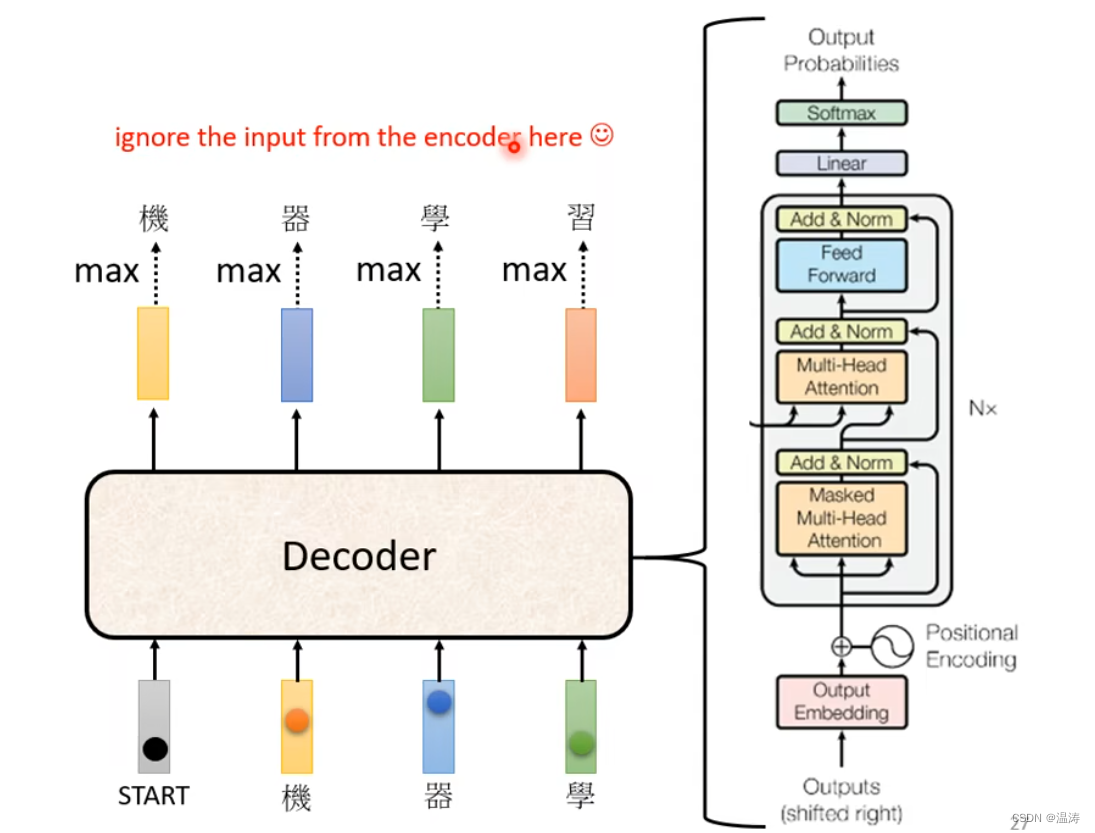
P11机器学习--李宏毅笔记(Transformer Decoder)Testing部分-EW帮帮网
Paper reading | VideoMAE: Masked Autoencoders are Data-Efficient ...
深入理解Transformer中的解码器原理(Decoder)与掩码机制 - 技术栈
Zero-Shot Controlled Generation with Encoder-Decoder Transformers | DeepAI
02 transformer:encoder结构和decoder结构 - 知乎
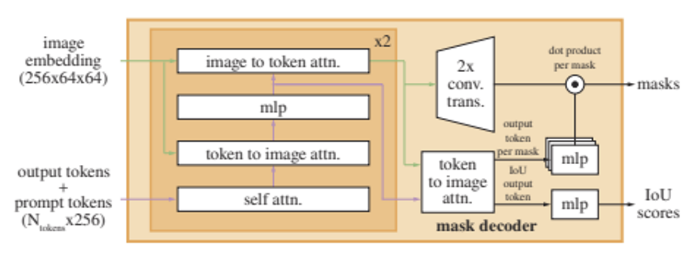
SAM
Vision Transformers (ViT) for Self-Supervised Representation Learning ...
Frontiers | Multi-head attention-based masked sequence model for ...
Multi-View Masked Autoencoder for General Image Representation
Transformer模型-学习笔记_transformer padding mask-CSDN博客
transformer-encoder architecture. | Download Scientific Diagram
(PDF) Optimizing Encoder-Only Transformers for Session-Based ...
Transformer模型-decoder解码器,target mask目标掩码的简明介绍_为什么要在encoder前做掩码-CSDN博客
mask former结构个人理解_maskformer 知乎-CSDN博客